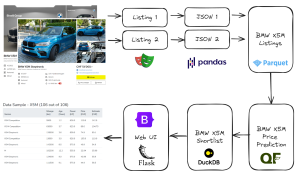
Relying solely on the outputs of machine learning (ML) models without a thorough verification can lead to unexpected results. Continuing from my previous DevLog, I embarked on a project to analyze car prices across various brands using data from AutoScout24.
In my efforts to ensure the robustness of my ML model, I included data from a vehicle I personally own – a reliable Renault Espace.
Looking at my daily estimations, my ML model estimated the price of a new hybrid-electric Renault Espace 1.2 E-Tech at nearly 50% below the market value listed.
50%?!? This discrepancy caught my attention and prompted a closer examination of the original advertisement on AutoScout24. The vehicle in question had several appealing attributes:
- Low mileage and recent manufacture
- Part of the latest generation of hybrid vehicles
- Offered by a reputable dealership
- Not involved in any previous accidents
- Accompanied by a 36-month warranty
Despite these factors, the model’s price estimation stood at approximately CHF 50k, aligning with the current price listed on the official Renault website but in stark contrast to its current listing price of CHF 32k. This has to be a great deal, right?

Upon further investigation, the root of the discrepancy became clear. The listing included a free-text subtitle by the seller stating the vehicle had hail damage – a critical detail our current data collection process had overlooked. If it looks too good to be true, it probably isn’t true.
This underscores the importance of verification when taking suggestions from ML models. While ML offers valuable insights, it’s crucial to cross-reference its outputs with additional data and real-world factors that may not be immediately apparent.
In ML and analytics, the principle of “trust, but verify” remains as relevant as ever. Ensuring the accuracy and reliability of ML-models is paramount to leveraging their full potential in making informed decisions.
How can we improve from here?
In order to avoid these kinds of issues in the future, I’m thinking about improving the “safety net” and to increase the trust in the prediction results. Potential solutions could include:
- Generate a list of keywords, that may trigger a warning on the listing given certain keywords (hail, damage, soaked, crashed etc.). This is a quick and dirty solution that might still miss some keywords and might not be very robust regarding typos.
- Run the free-text fields through an LLM and search for potential issues (probably more robust, but computationally more intensive)
And by the way, we’re expanding our team. If you need someone that builds robust data pipelines to make the best out of your data, let me know, and I’m happy to help (https://mydata.ch/services).
#ML #DataScience #Analytics #MachineLearning